Using FLamby with Substra
Introduction
Substra is an open source federated learning framework. It provides a flexible Python interface and a web app to run federated learning training at scale.
Substra main usage is a production one. It has already been deployed and used by hospitals and biotech companies (see the MELLODDY project for instance).
Yet Substra can also be used on a single machine on a virtually splitted dataset for two use cases:
debugging code before launching experiments on a real network
performing FL simulations
Substra was created by Owkin and is now hosted by the Linux Foundation for AI and Data.
This example illustrate the basic usage of SubstraFL, and propose a model training by Federated Learning using the Federated Averaging strategy on the TCGA BRCA dataset.
The objective of this example is to launch a federated learning experiment on the six centers provided on Flamby (called organization on Substra), using the FedAvg strategy on the baseline model.
This example does not use the deployed platform of Substra and will run in local mode.
Requirements
To run this example locally, please make sure to download and unzip in the same directory as this example the assets needed to run it:
Please ensure to have all the libraries installed, a
requirements.txt file is included in the example.
You can run the command: pip install -r requirements.txt to install
them.
Objective
This example will run a federated training on all 6 centers of the TCGA BRCA FLamby dataset.
This example shows how to interface Substra with FLamby.
This example runs in local mode, simulating a federated learning experiment.
Setup
We work with seven different organizations, defined by their IDs. Six organizations provide a FLamby dataset configuration. The last one provide the algorithm and will register the machine learning tasks.
Once these variables defined, we can create our different Substra Clients (one for each organization/center).
from substra import Client
from flamby.datasets import fed_tcga_brca
MODE = "subprocess"
# Create the substra clients
data_provider_clients = [Client(backend_type=MODE) for _ in range(fed_tcga_brca.NUM_CLIENTS)]
data_provider_clients = {client.organization_info().organization_id: client for client in data_provider_clients}
algo_provider_client = Client(backend_type=MODE)
# Store their IDs
DATA_PROVIDER_ORGS_ID = list(data_provider_clients.keys())
# The org id on which your computation tasks are registered
ALGO_ORG_ID = algo_provider_client.organization_info().organization_id
Data and metrics
Dataset registration
A Dataset is composed of an opener, which is a Python script with the instruction of how to load the data from the files in memory, and a description markdown file.
The Dataset object itself does not contain the data. The proper asset to access them is the datasample asset.
A datasample contains a local path to the data, and the key
identifying the
Dataset
in order to have access to the proper opener.py file.
To interface with FLamby, in the simple case of a single machine and a single runtime where clients are simple Python objects, the utilization of the opener and associated datasample method is implemented as a simple lookup table to indicate which center lives in which client. Substra is a library built to be deployed on a real federated network, where the path to the data is to the opener in order to load and read the data in a personalized way on the premises of the organization that owns the data.
As we directly load a torch dataset from Flamby, the folders
parameters is unused and the path usually leading to the data will point
out to an empty folder in this example.
As data can not be seen once it is registered on the platform, we set a Permissions object for each Assets, defining their access rights to the different data.
import pathlib
from substra.sdk.schemas import DatasetSpec
from substra.sdk.schemas import DataSampleSpec
from substra.sdk.schemas import Permissions
assets_directory = pathlib.Path.cwd() / "assets"
empty_path = assets_directory / "empty_datasamples"
permissions_dataset = Permissions(public=False, authorized_ids=[ALGO_ORG_ID])
train_dataset_keys = {}
test_dataset_keys = {}
train_datasample_keys = {}
test_datasample_keys = {}
for ind, org_id in enumerate(DATA_PROVIDER_ORGS_ID):
client = data_provider_clients[org_id]
# DatasetSpec is the specification of a dataset. It makes sure every field
# is well defined, and that our dataset is ready to be registered.
# The real dataset object is created in the add_dataset method.
dataset = DatasetSpec(
name="FLamby",
type="torchDataset",
data_opener=assets_directory / "dataset" / f"opener_train_{org_id}.py",
description=assets_directory / "dataset" / "description.md",
permissions=permissions_dataset,
logs_permission=permissions_dataset,
)
# Add the dataset to the client to provide access to the opener in each organization.
train_dataset_key = client.add_dataset(dataset)
assert train_dataset_key, "Missing data manager key"
train_dataset_keys[org_id] = train_dataset_key
# Add the training data on each organization.
data_sample = DataSampleSpec(
data_manager_keys=[train_dataset_key],
test_only=False,
path=empty_path,
)
train_datasample_key = client.add_data_sample(
data_sample,
local=True,
)
train_datasample_keys[org_id] = train_datasample_key
# Add the testing data.
test_dataset_key = client.add_dataset(
DatasetSpec(
name="FLamby",
type="torchDataset",
data_opener=assets_directory / "dataset" / f"opener_test_{org_id}.py",
description=assets_directory / "dataset" / "description.md",
permissions=permissions_dataset,
logs_permission=permissions_dataset,
)
)
assert test_dataset_key, "Missing data manager key"
test_dataset_keys[org_id] = test_dataset_key
data_sample = DataSampleSpec(
data_manager_keys=[test_dataset_key],
test_only=True,
path=empty_path,
)
test_datasample_key = client.add_data_sample(
data_sample,
local=True,
)
test_datasample_keys[org_id] = test_datasample_key
Metrics registration
A metric is a function used to compute the score of predictions on one or several datasamples.
To add a metric, you need to define a function that computes and return a performance from the datasamples (as returned by the opener) and the predictions_path (to be loaded within the function).
When using a Torch SubstraFL algorithm, the predictions are saved in the
predict function under the numpy format so that you can simply load them
using numpy.load.
After defining the metrics dependencies and permissions, we use the add_metric function to register the metric. This metric will be used on the test datasamples to evaluate the model performances.
import numpy as np
from torch.utils import data
from substrafl.dependency import Dependency
from substrafl.remote.register import add_metric
def tgca_brca_metric(datasamples, predictions_path):
config = datasamples
dataset = fed_tcga_brca.FedTcgaBrca(**config)
dataloader = data.DataLoader(dataset, batch_size=len(dataset))
y_true = next(iter(dataloader))[1]
y_pred = np.load(predictions_path)
return float(fed_tcga_brca.metric(y_true, y_pred))
# The Dependency object is instantiated in order to install the right libraries in
# the Python environment of each organization.
# The local dependencies are local packages to be installed using the command `pip install -e .`.
# Flamby is a local dependency. We put as argument the path to the `setup.py` file.
metric_deps = Dependency(pypi_dependencies=["torch==1.11.0","numpy==1.23.1"],
local_dependencies=[pathlib.Path.cwd().parent.parent], # Flamby dependency
)
permissions_metric = Permissions(public = False, authorized_ids = DATA_PROVIDER_ORGS_ID + [ALGO_ORG_ID])
metric_key = add_metric(
client=algo_provider_client,
metric_function=tgca_brca_metric,
permissions=permissions_metric,
dependencies=metric_deps,
)
Specifying the machine learning components
This section uses the PyTorch based SubstraFL API to simplify the machine learning components definition.
However, SubstraFL is compatible with any machine learning framework.
Specifying on how much data to train
To specify on how much data to train at each round, we use the Index Generator object.
We specify the batch size and the number of batches to consider for each
round (called num_updates).
from substrafl.index_generator import NpIndexGenerator
NUM_UPDATES = 16
SEED = 42
index_generator = NpIndexGenerator(
batch_size=fed_tcga_brca.BATCH_SIZE,
num_updates=NUM_UPDATES,
)
Torch Dataset definition
To instantiate a Substrafl Torch
Algorithm,
you need to define a torch Dataset with a specific __init__
signature, that must contain (self, datasamples, is_inference).
This torch Dataset is normally useful to preprocess your data on the
__getitem__ function.
class TorchDataset(fed_tcga_brca.FedTcgaBrca):
def __init__(self, datasamples, is_inference):
config = datasamples
super().__init__(**config)
SubstraFL algo definition
A SubstraFL Algo gathers all the elements that we defined that run locally in each organization. This is the only SubstraFL object that is framework specific (here PyTorch specific).
The torch dataset is passed as a class to the Torch Algorithms. Indeed, this torch Dataset will be instantiated within the algorithm, using the opener functions as datasamples parameters.
Concerning the
TorchFedAvgAlgo
interaction with **FLamby**, we
need to overwrite the _local_predict function, used to compute the
predictions of the model. In the default _local_predictprovided by
Substrafl, we assume that the __getitem__ method of the dataset
has a keyword argument is_inference used to only return X (and not
the tuple X, y).
But as the __getitem__ function is provided by
FLamby, the is_inference
argument is ignored. We need to overwrite the _local_predict to
change the behavior of the function, and can use this opportunity to
optimize the computation time of the function using knowledge of the
ouput dimension of the TGCA-BRCA dataset.
import torch
from substrafl.algorithms.pytorch import TorchFedAvgAlgo
model = fed_tcga_brca.Baseline()
class MyAlgo(TorchFedAvgAlgo):
def __init__(self):
super().__init__(
model=model,
criterion=fed_tcga_brca.BaselineLoss(),
optimizer=fed_tcga_brca.Optimizer(model.parameters(), lr=fed_tcga_brca.LR),
index_generator=index_generator,
dataset=TorchDataset,
seed=SEED,
)
def _local_predict(self, predict_dataset: torch.utils.data.Dataset, predictions_path):
batch_size = self._index_generator.batch_size
predict_loader = torch.utils.data.DataLoader(predict_dataset, batch_size=batch_size)
self._model.eval()
# The output dimension of the model is of size (1,)
predictions = torch.zeros((len(predict_dataset), 1))
with torch.inference_mode():
for i, (x, _) in enumerate(predict_loader):
x = x.to(self._device)
predictions[i * batch_size: (i+1) * batch_size] = self._model(x)
predictions = predictions.cpu().detach()
self._save_predictions(predictions, predictions_path)
Federated Learning strategies
A FL strategy specifies how to train a model on distributed data. The most well known strategy is the Federated Averaging strategy: train locally a model on every organization, then aggregate the weight updates from every organization, and then apply locally at each organization the averaged updates.
For this example, we choose to use the Federated averaging Strategy, based on the FedAvg paper by McMahan et al., 2017.
from substrafl.strategies import FedAvg
strategy = FedAvg()
Where to train and where to aggregate
We specify on which data we want to train our model, using the TrainDataNodes objets. Here we train on the two datasets that we have registered earlier.
The AggregationNode specifies the organization on which the aggregation operation will be computed.
from substrafl.nodes import TrainDataNode
from substrafl.nodes import AggregationNode
aggregation_node = AggregationNode(ALGO_ORG_ID)
train_data_nodes = list()
for org_id in DATA_PROVIDER_ORGS_ID:
# Create the Train Data Node (or training task) and save it in a list
train_data_node = TrainDataNode(
organization_id=org_id,
data_manager_key=train_dataset_keys[org_id],
data_sample_keys=[train_datasample_keys[org_id]],
)
train_data_nodes.append(train_data_node)
Where and when to test
With the same logic as the train nodes, we create TestDataNodes to specify on which data we want to test our model.
The Evaluation Strategy defines where and at which frequency we evaluate the model, using the given metric(s) that you registered in a previous section.
from substrafl.nodes import TestDataNode
from substrafl.evaluation_strategy import EvaluationStrategy
test_data_nodes = list()
for org_id in DATA_PROVIDER_ORGS_ID:
# Create the Test Data Node (or testing task) and save it in a list
test_data_node = TestDataNode(
organization_id=org_id,
data_manager_key=test_dataset_keys[org_id],
test_data_sample_keys=[test_datasample_keys[org_id]],
metric_keys=[metric_key],
)
test_data_nodes.append(test_data_node)
# Test at the end of every round
my_eval_strategy = EvaluationStrategy(test_data_nodes=test_data_nodes, rounds=1)
Running the experiment
We now have all the necessary objects to launch our experiment. Below a summary of all the objects we created so far:
A Client to orchestrate all the assets of our project, using their keys to identify them
An Torch Algorithms, to define the training parameters (optimizer, train function, predict function, etc…)
A Strategies, to specify the federated learning aggregation operation
TrainDataNode, to indicate where we can process training task, on which data and using which opener
An Evaluation Strategy, to define where and at which frequency we evaluate the model
An AggregationNode, to specify the node on which the aggregation operation will be computed
The number of round, a round being defined by a local training step followed by an aggregation operation
An experiment folder to save a summary of the operation made
The Dependency to define the libraries the experiment needs to run.
from substrafl.experiment import execute_experiment
# Number of time to apply the compute plan.
NUM_ROUNDS = 3
# The Dependency object is instantiated in order to install the right libraries in
# the Python environment of each organization.
# The local dependencies are local packages to be installed using the command `pip install -e .`.
# Flamby is a local dependency. We put as argument the path to the `setup.py` file.
algo_deps = Dependency(pypi_dependencies=["torch==1.11.0"], local_dependencies=[pathlib.Path.cwd().parent.parent])
compute_plan = execute_experiment(
client=algo_provider_client,
algo=MyAlgo(),
strategy=strategy,
train_data_nodes=train_data_nodes,
evaluation_strategy=my_eval_strategy,
aggregation_node=aggregation_node,
num_rounds=NUM_ROUNDS,
experiment_folder=str(pathlib.Path.cwd() / "experiment_summaries"),
dependencies=algo_deps,
)
2022-11-23 16:27:22,920 - INFO - Building the compute plan.
2022-11-23 16:27:22,937 - INFO - Registering the algorithm to Substra.
2022-11-23 16:27:22,965 - INFO - Registering the compute plan to Substra.
2022-11-23 16:27:22,966 - INFO - Experiment summary saved.
Compute plan progress: 0%| | 0/75 [00:00<?, ?it/s]
Plotting results
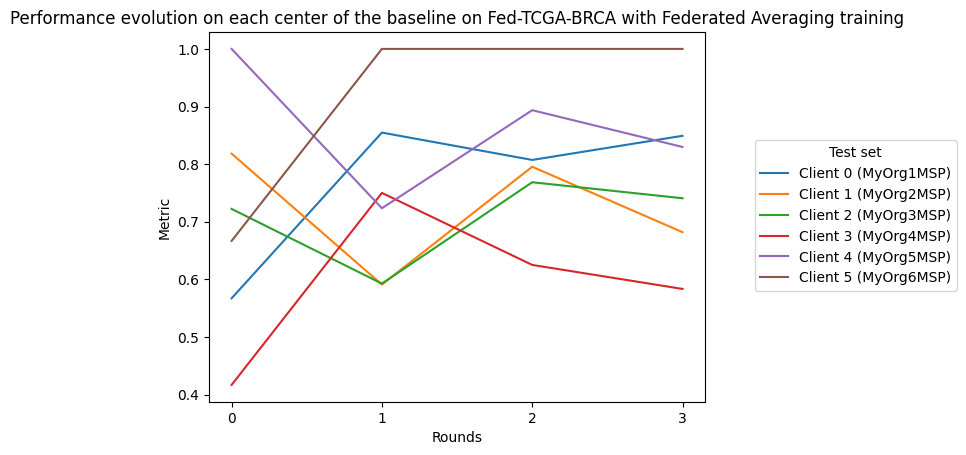
import pandas as pd
import matplotlib.pyplot as plt
plt.title("Performance evolution on each center of the baseline on Fed-TCGA-BRCA with Federated Averaging training")
plt.xlabel("Rounds")
plt.ylabel("Metric")
performance_df = pd.DataFrame(client.get_performances(compute_plan.key).dict())
for i, id in enumerate(DATA_PROVIDER_ORGS_ID):
df = performance_df.query(f"worker == '{id}'")
plt.plot(df["round_idx"], df["performance"], label=f"Client {i} ({id})")
plt.legend(loc=(1.1, 0.3), title="Test set")
plt.show()
Downloading a model
After the experiment, you might be interested in getting your trained model. To do so, you will need the source code in order to reload in memory your code architecture.
You have the option to choose the client and the round you are interested in.
If round_idx is set to None, the last round will be selected by
default.
from substrafl.model_loading import download_algo_files
from substrafl.model_loading import load_algo
client_to_dowload_from = DATA_PROVIDER_ORGS_ID[0]
round_idx = None
folder = str(pathlib.Path.cwd() / "experiment_summaries" / compute_plan.key / ALGO_ORG_ID / (round_idx or "last"))
download_algo_files(
client=data_provider_clients[client_to_dowload_from],
compute_plan_key=compute_plan.key,
round_idx=round_idx,
dest_folder=folder,
)
model = load_algo(input_folder=folder)._model
print(model)
print([p for p in model.parameters()])
Baseline(
(fc): Linear(in_features=39, out_features=1, bias=True)
)
[Parameter containing:
tensor([[ 0.0398, 0.6503, -0.2928, -0.1939, 0.0650, -0.1311, -0.0354, 0.0586,
-0.4715, -0.1761, -0.3675, -0.2748, 0.0926, -0.5276, -0.1857, -0.3742,
0.0829, 0.2343, -0.8615, 0.0280, -0.0237, -0.1865, -0.5507, 0.4314,
-0.3690, -0.2061, 0.0499, -0.2285, 0.1102, -0.0276, 0.2751, 0.5251,
-0.5587, -0.6355, -0.6012, -0.1639, -0.3266, 0.0889, 0.2282]],
requires_grad=True), Parameter containing:
tensor([-0.3652], requires_grad=True)]